Si on définit l’intelligence comme la faculté d’apprendre des choses nouvelles, de trouver des solutions à des problèmes se présentant pour la première fois, qui donc est plus intelligent que l’enfant? (*)
Certainement pas la machine.
- Elle est aussi incapable de résoudre un problème qui se pose pour la première fois qu’un chien dressé d’obéir à un commandement qu’il n’a jamais entendu.
- Par ailleurs, un humain et même la plupart des animaux n’ont pas besoin de dix mille références pour reconnaitre un chat.
- La machine est incapable de manipuler du “sens”, c’est l’humain qui lui instille des instructions qui en ont, et c’est l’humain qui perçoit du sens dans ce qu’elle produit.
Mais alors que fait-elle au juste et comment? Cette question parait incontournable pour envisager ce qu’elle ne sait pas faire et peut-être esquisser ce qu’elle pourrait ne jamais pouvoir accomplir.
qu’est-ce que le deep learning?
Le deep learning, ou apprentissage profond, se présente aujourd’hui comme le processus par lequel une forme d’intelligence deviendrait accessible à la machine. En quoi consiste-t-il? On en trouvera ici une présentation très pédagogique et très accessible, et ici une autre présentation par Yann LeCun, le chercheur de référence dans ce domaine. Pour résumer, disons que le deep learning fonctionne sur l’exploitation “de plus en plus savante” et “de plus en plus exigeante en puissance de calcul” des deux piliers historiques de l’informatique:
- les bases de données
- les boucles conditionnelles
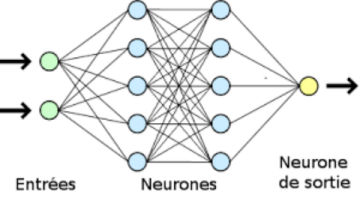
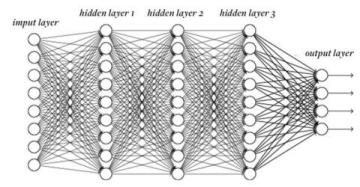
En fait, dans le deep learning, les boucles conditionnelles ne sont pas particulièrement complexes, elles sont surtout… beaucoup… beaucoup plus nombreuses que dans les processus traditionnels, traitées par des nappes d’algorithmes connues sous le terme quelque peu abusif de “réseaux de neurones” , et généralement représentées de la façon suivante:
L’exploitation des classiques de l’informatique par le deep learning est plus savante dans la mesure où elle incorpore ce qui est appelé le
“poids synaptique” , toujours par analogie avec les neurones du vivant, et sur lequel nous allons revenir un peu plus loin, à partir d’un exemple.
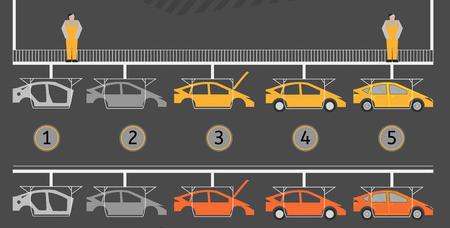
Résumons l’idée. Dans un de ses domaines d’application actuellement les plus actifs, celui de la reconnaissance d’images, une métaphore du deep learning serait une chaine de montage où les composants seraient “identifiés” les uns après les autres jusqu’à ce que le véhicule le soit complètement (1).
Cette compétence en induit très logiquement une autre: la machine peut recomposer les descripteurs qu’elle connait pour inventer une voiture qui n’existe pas, capacité déjà envisagée dans un
autre billet avec notamment la génération, par la machine, d’un “
faux Rembrandt”
En application de ce principe, on citera également la colorisation automatique d’images: une image en noir et blanc étant donnée, la machine retrouve des images du même type et “intuite”, à partir de là, les teintes à appliquer aux différents niveaux de gris.
Autant d’applications particulièrement spectaculaires qui pourraient nous faire oublier que sous ces dehors de création artistique, la machine ne fait rien d’autre qu’exploiter un énorme stock de références à l’intérieur duquel elle
“associe des similitudes”. En matière de deep learning, on peut dire que tout est là.
deep learning, intelligence & apprentissage
Comment la machine apprend-elle à associer des similitudes? En théorie selon deux principes :
- Au plus simple, on lui regroupe en amont un stock de références – par exemple des chevaux – de toutes les races, de toutes les couleurs, de toutes les tailles, vus sous tous les angles. Lorsqu’elle aura identifié ce que toutes ces références ont en commun, elle saura reconnaitre un cheval qu’elle n’a jamais vu. C’est ce qu’on appelle “l’apprentissage supervisé”. L’apprentissage supervisé correspond à un dressage: il est l’exacte réplique de ce qui amène un chien, dressé à cette fin, à détecter de la drogue ou de l’explosif. L’apprentissage supervisé fait du robot un exécutant.
- “L’apprentissage NON supervisé” consisterait pour la machine à identifier par elle-même, à l’intérieur d’un vaste ensemble, des sous-groupes présentant des similitudes. Elle construirait ainsi par association et sans le savoir, le groupe des “canards”, le groupe des “voitures” …etc. Cette performance serait la seule à relever d’une autonomie supposant une forme d’intelligence qui puisse être distinguée du dressage. Cet apprentissage ne pourrait s’opérer que sur la gestion des similitudes à l’intérieur d’un ensemble très vaste, voire illimité (définir des limites signifierait un retour à l’apprentissage supervisé). L’apprentissage non-supervisé se caractérise donc également – au moins dans ce billet – par l’emploi du conditionnel.
Rappelons-le une nouvelle fois: pour la machine, le “sens” n’existe pas. Son univers est donc littéralement celui de
l’absurde . Soumettre la machine à un apprentissage consiste donc, en tout premier lieu, à l’
empêcher de produire de l’absurde. Il faut garder à l’esprit que c’est dans l’absurde qu’elle va retomber si elle échappe, ne serait-ce qu’un instant, au mode opératoire acquis par l’apprentissage.
le deep learning et le poids synaptique
Le deep learning intègre non seulement les conditions, mais également leurs poids relatifs (dit “poids synaptique”), celui qu’il faut leur accorder pour décider qu’un élément appartient ou non à un ensemble donné. Par exemple, pour identifier un poisson, la présence de nageoires pourra être posée comme plus importante que la forme de la bouche ou des yeux, même si ces derniers peuvent avoir des aspects spécifiques dont il faut tenir compte. Avec l’intégration du poids synaptique, le réseau de neurones envisagé ci-dessus s’apparente alors à une table de mixage (2)
L’ajustement global de l’ensemble des “curseurs” a évidemment pour finalité d’obtenir, en sortie, le taux d’erreur le plus faible possible. .
Exemple
Imaginons que nous fassions manuellement ce que le réseau de la machine réalise automatiquement à savoir le réglage global de curseurs qui nous donnera à voir, dans un immense stock d’images, avec le taux d’erreur le plus réduit possible, un sous-ensemble particulier: ici celui des poissons.
Posons qu’une première configuration nous offre une collection de poissons très classiques comme le gardon, le chevesne ou la daurade.
En jouant sur le curseur qui autorise des formes plus anguleuses, on va pouvoir incorporer à notre collection d’autres éléments comme le requin et le thon.
Nous constatons alors que la couleur a manifestement un poids trop important qui limite beaucoup la collection. En le réduisant, on va pouvoir incorporer, par exemple, la limande et le poisson rouge.
Il faudra alors réduire le poids d’un second critère de couleur, le critère “uni”, et ajuster le curseur de saturation pour voir s’ajouter certains poissons exotiques.
Un réglage un peu plus fin des paramètres de formes et de couleurs déjà effectués permettra d’incorporer des poissons du type de celui-ci.
La question qui va cependant finir par se poser est: que va-t-il se passer si nous agissons sur les curseurs qui permettraient d’incorporer à notre ensemble, la raie-léopard, le poisson-globe, le congre et la rascasse?
- soit une intervention humaine va imposer à l’algorithme de les intégrer un par un, en dehors de toute boucle conditionnelle.
- soit on va laisser agir librement l’algorithme et… faire exploser le système… car la machine va rejoindre son univers de l’absurde, exclure certains poissons précédemment détectés, mais devenus incompatibles avec les nouveaux réglages et intégrer dans le groupe des poissons: le boa, la libellule, la soucoupe volante, le ballon de football et des milliers de créatures et objets ressemblant à ceux-ci… car il n’y a aucune raison pour qu’il en aille autrement si l’apprentissage n’est pas supervisé.
le deep learning et la question des similitudes
On m’objectera que tous ces poissons ont en commun de vivre sous l’eau et qu’on pouvait commencer par là. Admettons que la critique soit recevable pour les poissons, quoiqu’un poisson ne cesse pas d’en être un quand il arrive chez le poissonnier, mais on sent bien que le problème est beaucoup plus profond. Tellement profond même que le philosophe Ludwig Wittgenstein lui a accordé une place centrale dans sa pensée où il l’a notamment illustré avec l’exemple du jeu
Considère par exemple les processus que nous nommons jeux…\… Regarde les jeux de pions et leurs divers types de parentés. Passe ensuite aux jeux de cartes; tu trouveras bien des correspondances entre eux et les jeux de la première catégorie, mais tu verras aussi que de nombreux traits communs aux premiers disparaissent, tandis que d’autres apparaissent. Si nous passons ensuite aux jeux de balle, ils ont encore beaucoup de choses en commun avec les précédents, mais beaucoup d’autres se perdent…
Encore n’évoque-t-il pas les jeux de pistes, les jeux de rôles et bien sûr … les jeux vidéos (à son époque il avait des excuses). Ce qui ne l’empêche pas de terminer sa démonstration par:
le concept de « jeu » est non délimité, tu ne sais pas vraiment ce que tu entends par « jeu ».
La non-délimitation des concepts apparait, à l’évidence, comme le coeur du problème. Car, par la
théorie des ensembles , les mathématiques rejoignent cette conclusion philosophique.
Un ensemble peut être défini en extension, c’est-à-dire en donnant la liste de ses éléments, ou en compréhension c’est-à-dire par une propriété caractérisant ses éléments.
Dans les deux cas, son élaboration par la machine ne peut être que supervisée. Par elle-même, la machine ne saurait construire des ensembles qu’à partir d’un principe de similitude par lequel toute délimitation est impossible.
La relation de similitude ne peut pas construire des ensembles finis. Par le jeu des similitudes, toutes les créatures et tous les objets existants finiront reliés indirectement à tous les autres.
Exemple: qui a-t-il de plus dissemblable qu’un rouge-gorge et une baleine bleue?
La relation de similitude nous mène pourtant très rapidement de l’un à l’autre.
Entièrement dépendante du principe de similitude, y compris dans les processus très évolués liés au deep learning, la machine n’est donc pas en mesure de
délimiter de façon autonome son espace de travail.
et alors… qu’est-ce que çà change?
Il serait donc impossible à la machine d’apprendre toute seule?
Elle peut apprendre seule, par le deep learning, mais à l’intérieur d’un “espace de travail” préalablement délimité… par l’humain. Ce qui lui laisse néanmoins la possibilité de réaliser des choses étonnantes. Prenons un exemple dans l’imagerie médicale: on peut tout à fait imaginer qu’une machine ayant appris à distinguer des cellules cancéreuses puisse identifier, dans les cellules saines, des sous-ensembles présentant une similitude que l’humain n’aurait pas détectée et qui s’avérerait annoncer les futures cellules cancéreuses.
Ce que la machine ne pourra jamais faire de façon autonome c’est
étendre son espace de travail “au-delà” des limites qui lui auront été fixées, car au-delà de ces limites n’existe, pour elle, que l’absurde.
Elle ne saura donc jamais travailler que sur des “sous-ensembles”. Ce qui signifie:
- qu’elle pourra construire une arborescence de compétences en créant des sous-ensembles à l’intérieur d’autres sous-ensembles poussant ainsi très loin un savoir de spécialité.
- que de multiples spécialités pourront être regroupées dans une même machine, ce qui ne la rendra pas pour autant… intelligente. Un chien dressé à détecter de la drogue pourrait aussi savoir détecter des explosifs ou le cancer, il pourrait également comprendre, de lui-même, que quand on lui met la truffe dans la neige on attend de lui qu’il recherche les victimes d’une avalanche. Ce serait un chien d’exception… mais ce ne serait toujours qu’un chien.
- le robot ne pourra donc jamais accéder à une approche généraliste. Il ne sera toujours qu’un exécutant, même s’il est un… remarquable exécutant.
Cela ne limite pas véritablement les “possibles techniques” du robot, mais cela modifie surtout
l’idéologie qui lui est associée. Le robot pourra peut-être tout faire, mais il ne pourra jamais travailler qu’en
dessous de l’humain. Il dépassera l’humain sur des capacités particulières, ce qui est la raison d’être de… toutes les machines. Il sera plus perfectionné que les machines qui l’ont précédé… comme toutes les machines.
mais pourquoi l’humain fait-il aussi facilement ce qui est inaccessible au robot?
Albert Einstein avait des intuitions fulgurantes, mais aussi le goût des bons mots. On serait tenté de classer l’aphorisme suivant dans la seconde catégorie… et ce serait à tort:
Les machines un jour pourront résoudre tous les problèmes, mais jamais aucune d’entre elles ne pourra en poser un.
Car c’est bien la problématique qui détermine “l’espace de travail” de la réponse. En posant un problème de quelque nature que ce soit, on détermine ce qui est utile ou non dans les ressources dont nous disposons pour le résoudre.
Le problème détermine le besoin et cette relation n’est réciproque que pour le vivant. Entendons-nous bien: nous parlons ici du besoin qui redistribue et coordonne en permanence nos pensées et nos actions, pas de la capacité pour une machine de dire «ma batterie doit être rechargée».
Le vivant implique le besoin. Le besoin suppose le vivant.
Le besoin filtre nos perceptions, mobilise et remobilise nos ressources “à la volée” dans le temps, qu’il concerne le domaine physique, mental, intellectuel, social… qu’il soit amené à composer avec la curiosité, l’envie, la peur, la volonté de puissance, l’instinct de survie…
Une machine n’a pas de besoin … donc pas de problème … donc pas d’intelligence.
Si élaboré qu’il puisse être, le deep learning ne suffit pas. Pour fabriquer de l’intelligence, il faut fabriquer du vivant. C’est la conclusion à laquelle nous étions arrivés, par une tout autre voie, dans le
billet précédent.
(1) copyright – credit photo 123RF – annyart
(2) copyright – credit photo 123RF – Tomasz Wyszolmirski












Clément
Super article, merci beaucoup.